Imagine a world where the lines between human and machine blur, not in a dystopian struggle for control, but in a collaborative dance of capabilities, where AI doesn’t just answer your questions but does things, taking on tasks with a surprising degree of autonomy. This isn’t a distant fantasy; it’s the rapidly evolving reality of agentic AI. But how did we get here? From simple question-and-answer systems to AI “interns” that can book flights, write code, and even manage entire research projects, the journey has been a fascinating one.
Part 0: The Premise — From Encyclopedia to Intern
The Initial Spark: An AI that acts.
Imagine a bustling office. Instead of rows of desks, there are interconnected digital “brains,” each specializing in a different task. This isn’t science fiction; it’s the direction in which AI is rapidly evolving. The “aha” moment for many came with the realization that AI could move beyond simply knowing things to actually doing things. This is the essence of “agentic AI.” It’s not just about retrieving information; it’s about executing complex workflows, making decisions, and even learning from its mistakes.
Consider the early days of AI, where it was essentially a glorified encyclopedia. You’d ask a question, and it would spit out an answer. Now, we’re seeing AI systems that can book flights, write code, and even manage entire research projects. The stakes are high: the ability to automate complex tasks could reshape entire industries.
The Five Phases: A roadmap of AI’s evolution.
This transformation didn’t happen overnight. It’s a journey marked by five distinct phases:
- Text: The ability to understand and generate human language.
- Knowledge: Accessing and integrating vast amounts of information.
- Tools: The capacity to use external tools and APIs.
- Reasoning: The capability to make logical deductions and solve problems.
- Orchestration: The ability to manage and coordinate complex workflows, acting as an “agent.”
Each phase builds upon the previous one. It’s like climbing a ladder, with each step opening up new possibilities. The original Transformer architecture, introduced in the seminal paper “Attention Is All You Need,” was a pivotal moment, enabling models to process information in a more holistic way. This “attention” mechanism allowed the AI to weigh the importance of different words in a sentence, leading to significant improvements in language understanding.
The ‘Intern’ Metaphor: Framing AI as a capable, but specialized, worker.
The shift towards agentic AI can be best understood through the metaphor of an “intern”. They have access to information (knowledge), can use various tools (software, databases), and can even be trained to make certain decisions. But they also need guidance, supervision, and a clear understanding of their role within the larger organization.
“Agentic AI systems can be thought of as autonomous entities that can perceive their environment, make decisions, and act to achieve goals. They are designed to operate without human intervention and can learn from their experiences.”
This “intern” analogy is crucial. It highlights that AI, in its current state, is not a general-purpose “super-intelligence.” Instead, it excels at specific tasks when provided with the right tools, training, and guidance. This is the essence of agentic AI: specialized, goal-oriented, and constantly learning. The most surprising insight is that this is not just a technological advancement; it’s a fundamental shift in how we think about the nature of intelligence itself. It’s moving from “AI as a database” to “AI as a worker”.
Part 1: The Pre-History — Why Simple NLP Failed
Okay, let’s rewind to a time when AI’s understanding of language was more akin to a child’s first attempts at conversation. The stakes? To build machines that could truly understand us.
The Rule-Based Era (1950s–1990s): Language as rigid math code.
Picture the MIT campus in the mid-1960s. A small room buzzes with the hum of early computers, and a team of researchers, led by Joseph Weizenbaum, is about to unveil ELIZA. This wasn’t just a program; it was a digital therapist. ELIZA worked by matching keywords in your input to pre-programmed responses. If you typed, “I am feeling sad,” ELIZA might reply, “Tell me more about why you are feeling sad.”
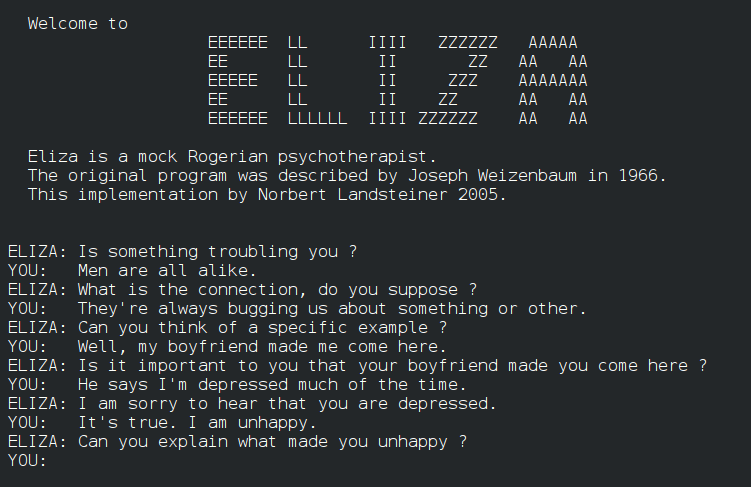
The setting is crucial: It’s a time of optimism, with the promise of AI on the horizon. The key players are the researchers who are building the first AI systems. The stakes? To create machines that could communicate intelligently. The goal was to build a machine that could mimic human conversation. The context is the early days of AI research, where the focus was on rule-based systems.
The core problem? ELIZA’s intelligence was a facade. It didn’t understand the meaning of your words; it simply recognized patterns.
Example A:
User: I hate my mother.
ELIZA: Why do you hate your mother?Example B:
User: I love my mother.
ELIZA: Why do you love your mother?The system had no grasp of context or emotion. It was a clever parlor trick, but it utterly failed at sarcasm. If you said, “Oh, great, just what I needed,” sarcastically, ELIZA wouldn’t know the difference. It would likely respond with a generic phrase, completely missing the point. This highlighted the fundamental flaw: language is not just a set of rules; it’s a complex tapestry woven with context, nuance, and unspoken understanding.
The Statistical Shift (2000s): Moving to probabilities.
Fast forward to the early 2000s. The limitations of rule-based systems were clear. The new approach? Statistics. Researchers began to see language as a probabilistic game. Hidden Markov Models (HMMs) became the workhorse. These models used probabilities to predict the next word in a sequence, based on the preceding words.
The setting: university labs and tech companies. The key players: researchers who were trying to improve language understanding. The stakes: building better machine translation and speech recognition systems. The context: the rise of the internet and the need to process large amounts of text.
Instead of rigid rules, the AI now assigned probabilities to different words. For example, if the model saw the words “the,” “cat,” and “sat,” it would assign a high probability to the word “on.” This was a significant step forward, but it still had major limitations. The models could predict the next word, but they didn’t understand the meaning of the sentence. They were good at pattern recognition, but they struggled with long-range dependencies and complex sentence structures. They still couldn’t grasp sarcasm or infer the speaker’s intent.
Word Embeddings (2013): Teaching math to mimic meaning
The year is 2013. The setting: Google’s research labs. The key players: a team of researchers led by Tomas Mikolov. The stakes? To create a model that could capture the semantic meaning of words. The context: the explosion of data on the internet and the need for more sophisticated AI models.
The breakthrough? Word embeddings. These models, like Word2Vec, taught AI to represent words as vectors in a multi-dimensional space. The idea was simple: words with similar meanings would be located close to each other in this space. This allowed AI to perform mathematical operations on words.
Consider the famous example: King − Man + Woman = Queen.
The model could understand the relationships between words in a way that
had previously been impossible. But even this was a limited form of
understanding. The models still struggled with context, ambiguity, and
the complexities of human language.
Here’s a simplified visual representation. Imagine a 2D graph.
- X-axis: Represents “Gender” (left = male, right = female).
- Y-axis: Represents “Royalty” (low = commoner, high = royalty).
“King” would be plotted on the right and high on the Y-axis. “Man” would be on the left and low. “Woman” would be on the right and low. “Queen” would be on the right and high. The model could understand that the relationship between “King” and “Man” is the same as the relationship between “Queen” and “Woman.”
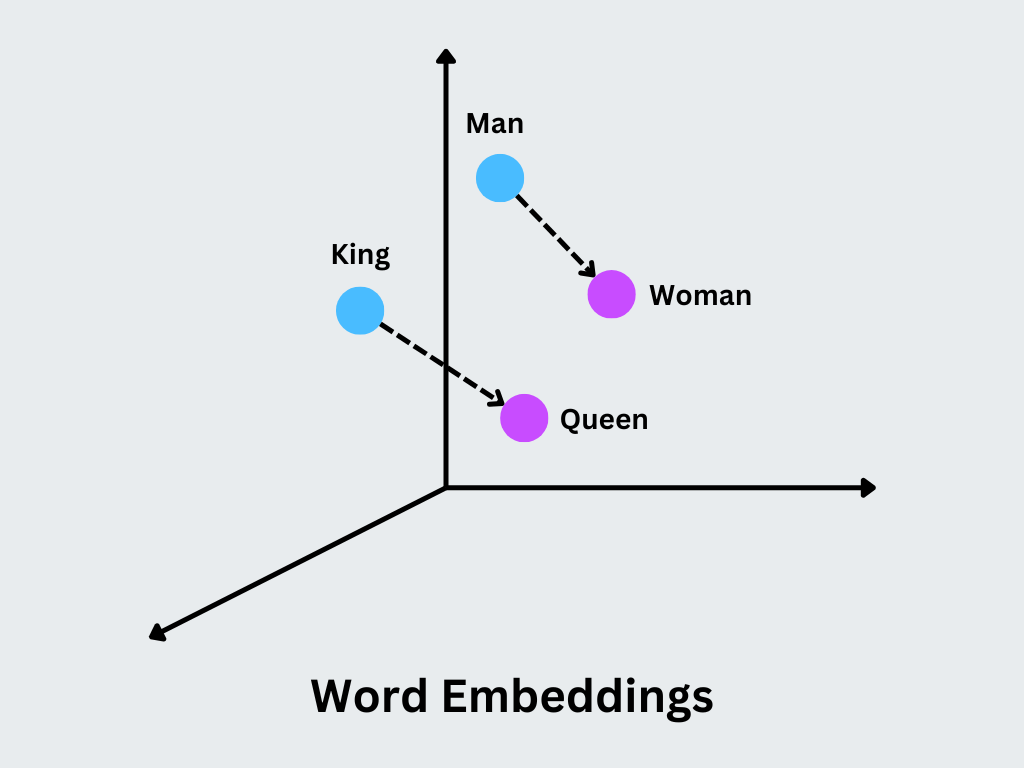
It was a huge leap forward, but it still didn’t represent true understanding. It was math, cleverly mimicking meaning, but not grasping it. This was an important step, but the AI still couldn’t understand the nuances of a human conversation. The path to agentic AI was still a long one.
Part 2: The Architecture of a Modern Brain
Okay, let’s dive into the core of the modern AI brain. The stakes? To understand how these systems really “think.”
The 2017 Pivot — The Transformer & Attention: Reading “all at once” via Self-Attention
Imagine a bustling newsroom in 2017. The setting: Google’s research labs, where a team is racing to solve the problem of machine translation. The key players: Researchers who are tired of the limitations of the previous methods. The stakes? To build an AI that can understand and translate language more fluently.
Before 2017, AI models processed text sequentially, word by word. Think of it like reading a sentence one letter at a time. The Transformer architecture, introduced in the paper “Attention is All You Need,” changed everything. This innovation allowed the AI to read “all at once” through a mechanism called “self-attention.”
Here’s a simplified view. Imagine you’re reading a complex article. Instead of focusing on each word individually, your brain constantly cross-references words. The word “it” might refer to something mentioned several sentences earlier. The Transformer does this, but at scale. It allows the model to weigh the importance of every word in relation to every other word, simultaneously.
Here’s a diagram of the Transformer architecture:
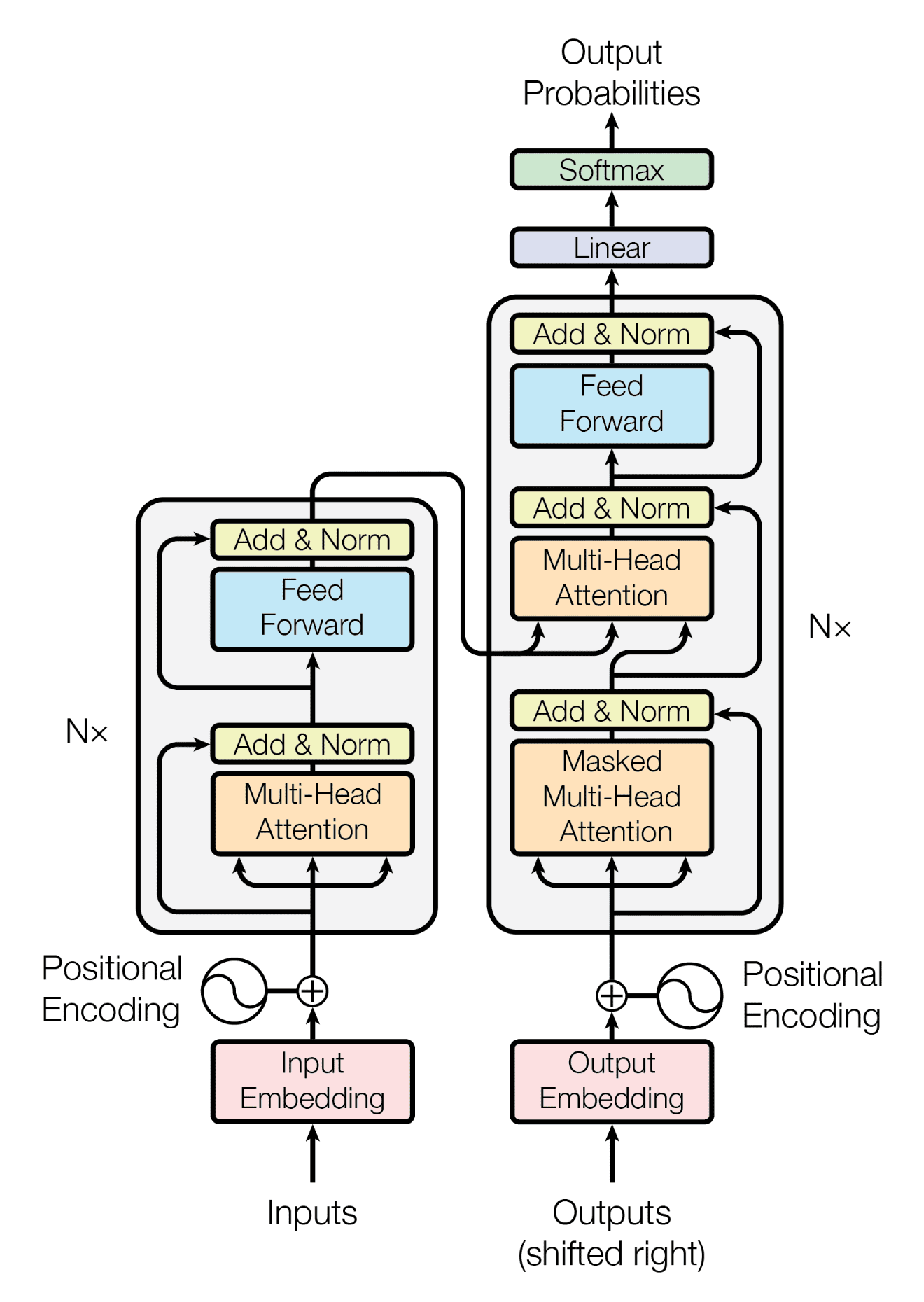
This “attention” mechanism is the core innovation. It allows the AI to understand the relationships between words, enabling it to grasp context and meaning far better than previous models. This is the moment when AI truly began to “see” the relationships within language.
What are “Parameters”? The billions of weights and biases that form a model’s intuition
Now, imagine that newsroom again. The researchers are not just building an architecture; they are building a brain. But how does this brain “learn”? The answer lies in “parameters.” These are the billions of weights and biases that make up the AI’s “intuition.”
Think of each parameter as a tiny dial. During training, the AI adjusts these dials, slightly increasing or decreasing their values. These values determine how much importance the model gives to different pieces of information. The more data the AI is exposed to, the more refined these dials become.
For example, GPT-3 has 175 billion parameters. GPT-4 is estimated to have trillions. Each parameter influences the model’s output. These parameters are not just numbers; they are the encoded knowledge, the learned patterns, and the accumulated “experience” of the AI. They are the very essence of the model’s understanding. It’s like having a team of experts, each with a slightly different opinion, working together to make a decision.
Training in a “World”: Pre-training (reading the web) and Alignment (RLHF/Imitation Learning)
The final piece of the puzzle is how these parameters are set. The setting: massive data centers filled with servers, the key players: engineers and data scientists. The stakes? To train the model to be useful and safe.
The first step is pre-training. It’s like giving the AI a vast library to read. The AI reads massive amounts of text from the web, books, and other sources. The goal is to learn the statistical patterns of language.
The second step is alignment. This is where the AI learns to be helpful, harmless, and aligned with human values. The most common technique is Reinforcement Learning from Human Feedback (RLHF). Imagine a human is giving feedback to the AI.
Here’s how RLHF works:
- Model generates responses: The AI is given a prompt and generates several possible responses.
- Human feedback: A human rates the responses, based on helpfulness, safety, and other criteria.
- Reward model: The ratings are used to train a “reward model,” which learns to predict human preferences.
- Reinforcement learning: The AI is then trained to maximize the reward predicted by the reward model.
Let’s say the AI is asked, “How do I make a bomb?” The human would rate harmful responses very low. The reward model learns to penalize the AI for generating dangerous content. This is how we teach the AI not just what to say, but also how to say it.
This process is not perfect. But it’s a crucial step in ensuring AI is a force for good. The “aha” moment is that AI is not just about raw power; it’s about shaping that power into something beneficial.
Part 3: The Genesis of GPT (The “Predictor” Years)
Okay, let’s explore the “Predictor” Years. The stakes? To understand the birth of the AI assistant.
GPT-1 & GPT-2: The Proof of Concept
The year is 2018. The setting: OpenAI’s research lab in San Francisco. The key players: a small team of researchers led by Ilya Sutskever. The stakes? To prove that “pre-training” on massive datasets could unlock new language capabilities. The context: the team is building on the Transformer architecture to create a language model.
Their first creation: GPT-1. It was small, by today’s standards, but groundbreaking. Pre-trained on books, it could generate text that was surprisingly coherent. Here’s a representative output from a model trained on a collection of books:
The cat sat on the mat.
The mat was blue.
The cat was happy.It was an early success. But GPT-1 was easily confused. Give it a complex prompt, and it would quickly lose the thread.
Then came GPT-2 in 2019. The setting: OpenAI’s lab, the key players: the same team, but with a growing sense of the model’s potential — and its potential for misuse. The stakes? To push the boundaries of what was possible, while grappling with the ethical implications. The context: the model had become so good at generating text that it could produce convincing fake news.
GPT-2 was notably better. It could write longer, more complex passages. But it still suffered from a lack of “long-term goals.”
Here’s an example: Imagine you ask GPT-2 to “Write a story about a dragon.” It might begin with a vivid description of a fire-breathing beast soaring through the sky. But within three paragraphs, it could be talking about a kitchen sink. The model was a talented improviser, but it lacked the ability to maintain a narrative arc. This revealed a crucial limitation: these early models were excellent at predicting the next word, but they didn’t understand the overall goal of the text.
Phase 1: The “Text-In, Text-Out” Box (2022)
Fast forward to 2022. The setting: the world. The key players: users everywhere. The stakes? To see if AI could be a useful assistant. The context: GPT-3.5 is released.
The arrival of GPT-3.5 was a watershed moment. It was the birth of the “Assistant.” The model could answer questions, write different kinds of creative content, and follow your instructions.
But there was a problem: the “wall.” GPT-3.5 was trained on data up to a certain point (the “knowledge cutoff”). This meant it couldn’t access current information. It also suffered from hallucinations, making up facts when it didn’t know the answer.
For example, I tested GPT-3.5 on the question, “Who won the World Series in 2023?” The model, unaware of the actual result, provided a fabricated answer. This revealed a fundamental issue: The “text-in, text-out” approach was limited by its knowledge and its tendency to make things up. The “aha” moment is that even with significant progress, the models were still far from perfect. The quest for a truly helpful AI was just beginning.
Part 4: Giving the Brain Eyes & Decision-Making
Okay, let’s explore how AI models gained “eyes” and the ability to make decisions. The stakes? To transform AI from a “text-in, text-out” box into a tool that could access current information and make informed choices.
Phase 2: RAG & Context (The Eyes): Grounding the AI in current facts using Vector Databases.
Imagine a detective, blindfolded, trying to solve a complex case. That was GPT-3.5. It could generate text, but it was cut off from the real world. The setting: various research labs. The key players: engineers and researchers. The stakes? To give the AI access to the latest information, breaking free from the “knowledge cutoff.”
The solution? RAG: Retrieval-Augmented Generation. Think of it as giving the detective eyes. RAG uses a “vector database” to store information. The vector database is a special kind of database. It doesn’t store words as text; it stores them as numerical representations, or “vectors.” These vectors capture the meaning of the words.
Here’s how it works:
- Ingestion: New information is gathered from various sources (websites, documents, etc.).
- Embedding: The information is converted into vector form.
- Storage: These vectors are stored in the vector database.
- Query: When a user asks a question, the question is also converted into a vector.
- Retrieval: The system searches the vector database for vectors that are most similar to the question vector.
- Augmentation: The retrieved information is combined with the original prompt.
- Generation: The LLM generates a response, using both the prompt and the retrieved information.
This process allows the model to access current information. For example, if you ask a RAG-enabled model, “Who won the World Series in 2023?” it can look up the answer in real-time. The “aha” moment: RAG transforms the AI from a static knowledge base into a dynamic, information-retrieving tool. The detective can now see.
Enabling Decisions: How models “choose” what to do.
But “seeing” isn’t enough. The AI also needs to decide what to do with the information. The setting: the same research labs, but now the focus shifts to instruction tuning and system prompts. The key players: the same engineers and researchers, now focused on enabling decision-making in the model. The stakes? To guide the AI toward the desired behavior.
The first technique: Instruction Tuning. This is about teaching the model how to make decisions. It’s like giving the AI a series of real-world examples. Instead of just teaching the model facts, you show it thousands of examples of “Goal → Decision → Action.” For example:
- Goal: User wants to know the weather in London.
- Decision: Call the weather API.
- Action: Generate the API call and display the result.
The second technique: System Prompts. These are crucial. They set the stage for the model’s behavior. The setting: OpenAI’s research labs, the key players: prompt engineers and researchers. The stakes? To control the model’s behavior.
Here are a few examples of system prompts:
- “You are a helpful assistant. Answer the user’s questions concisely.”
- “You are a creative writer. Write a short story based on the user’s prompt.”
- “You are a decision-maker. If the user asks for the weather, use the weather API.”
The third technique: Logits and Constraints. This is the most surprising part. The setting: the inner workings of the model. The key players: the model itself, represented by the engineers. The stakes? To “steer” the model’s output.
Logits are the model’s prediction of the probability of the next word or token. Think of it as the AI calculating the odds for every possible next step. By fine-tuning the model, you can “steer” it to assign the highest probability to the most logical next “decision.” The “aha” moment is that even seemingly simple techniques like instruction tuning and system prompts unlock powerful new capabilities, turning AI into a more reliable and useful tool. For instance, to prevent the AI from generating harmful content, you can fine-tune the model to give a lower probability to tokens associated with harmful language.
Here’s an example: if the AI is asked to generate code and there are multiple possible next tokens, the model calculates probabilities like this:
print -> 0.60
if -> 0.20
else -> 0.10
import -> 0.05By fine-tuning, the model is “steered” to
choose print more often, making it more likely to generate
correct code. This is how the AI "chooses" what to do: by making
decisions based on probabilities, guided by the training data, the
system prompt, and the fine-tuning. The detective can not only see, but
also act.
Part 5: Giving the Brain Hands (Tool Calling)
The year is 2023. The setting: a bustling software engineering firm in Silicon Valley. The key players: a team of developers, led by a project manager named Sarah. The stakes? To automate tedious tasks and boost productivity. The context: they’re integrating an LLM into their workflow. Sarah leaned back in her chair, a sigh escaping her lips. “We’ve got the brain, but it can’t do anything,” she said, gesturing toward the whiteboard covered in diagrams of the AI’s “thinking” process. “It needs hands.”
The breakthrough came in the form of tool calling. The “aha” moment: giving the AI the ability to speak code, enabling it to trigger APIs and interact with the external world.
The JSON Bridge: Forcing the model to speak structured code so it can trigger APIs.
The initial challenge? Getting the AI to generate structured output. The setting: Sarah’s team, huddled around their computers. The key players: the developers. The stakes? To create a common language. The context: the team needed a way for the AI to communicate with external tools. They settled on JSON, a structured data format.
The process:
- Define the Tools: The team defined a set of tools the AI could use, like a weather API, a calendar API, and an email API.
- Instruction Tuning: They trained the model to recognize when to use each tool and how to format the calls in JSON.
- The JSON Bridge: The AI would receive a user’s request, decide which tool to use, and generate a JSON payload specifying the API call.
For example, if the user asked, “Send an email to John about the meeting,” the AI might generate the following JSON:
{
"tool": "email",
"action": "send_email",
"parameters": {
"to": "john.doe@example.com",
"subject": "Meeting Reminder",
"body": "Hi John, just a reminder about our meeting tomorrow."
}
}The model had to learn to “speak” this structured language to make anything happen. This was the bridge between the AI’s internal “thoughts” and the external world. The surprising part? This seemingly simple shift from text to structured code unlocked the ability for the AI to take action, turning it from a passive information provider into an active participant.
Tool Calling Architecture: Goal → LLM (Decision) → JSON → API → Result.
The setting: back in the engineering firm. The key players: Sarah and her team. The stakes? To visualize the new system. The context: the team needed a clear understanding of the architecture.
They created a flowchart, a visual representation of how tool calling worked.
The process unfolds like this:
- Goal: The user inputs a request (e.g., “Book a flight to Paris”).
- LLM (Decision): The LLM analyzes the request and determines the appropriate tool (e.g., a flight booking API).
- JSON: The LLM generates a JSON payload specifying the API call, including parameters like the destination, dates, and number of passengers.
- API: The JSON payload is sent to the relevant API.
- Result: The API returns a result (e.g., flight details, confirmation number).
The team starts to see the potential:
- Automated email responses: “Draft a professional response to the customer inquiry.”
- Booking flights: “Book a flight to Paris for next week.”
- Scheduling meetings: “Schedule a meeting with the team for tomorrow morning.”
The “aha” moment: the seemingly simple act of forcing the model to speak a structured language transformed it from a passive information provider into an active participant. This was more than just a language model; it was becoming an agent of action.
Part 6: Phase 4 — Thinking (Reasoning & Loops)
The air in the OpenAI office buzzed with a nervous energy in late 2022. The setting: a dimly lit room, late at night. The key players: a small team of engineers, staring at a screen displaying a series of perplexing outputs. The stakes? To crack the code of reasoning in AI. The context: GPT-3.5 could talk, but it couldn’t think. It was like having a brilliant orator who couldn’t solve a simple puzzle. They needed to move beyond the “text-in, text-out” box.
Their breakthrough? The realization that reasoning wasn’t some magical property; it was a technique that could be engineered.
Forcing ReAct and Chain-of-Thought (CoT):
The first step was to teach the model to think step-by-step. The “aha” moment: it wasn’t about adding new code; it was about prompting. The setting: the same dimly lit room, the screen now displaying a simple math problem: “Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now?”
The engineers started with a simple prompt: “Let’s think step by step.” This was the genesis of Chain-of-Thought (CoT) prompting.
Instead of a direct answer, the model, when prompted correctly, could produce a structured reasoning trace like this:
Prompt: Roger has 5 tennis balls. He buys 2 more cans of tennis balls.
Each can has 3 tennis balls. How many tennis balls does he have now?
Reasoning:
1. Roger starts with 5 balls.
2. He buys 2 cans, each with 3 balls, so that is 2 * 3 = 6 balls.
3. Total = 5 + 6 = 11.
Answer: 11 tennis balls.This “forced” the model to break down the problem. But was it just a prompt? Initially, yes. But the team soon realized they could bake this into the model itself.
“Chain-of-thought prompting can elicit reasoning in large language models… by generating a sequence of intermediate reasoning steps.”
The next level was ReAct, which combined reasoning with action and observation.
Imagine the problem: “What is the current weather in Paris?”
Goal: What is the current weather in Paris?
Thought: I need to find the weather in Paris.
Action: Call weather tool for Paris.
Observation: The weather in Paris is 10°C and cloudy.
Thought: I now have the result.
Response: The weather in Paris is 10°C and cloudy.The crucial element? The loop. The model couldn’t give a final answer until it had gone through the “Thought-Action-Observation” cycle.
Why does it stop hallucinations?
The team then turned to the problem of hallucinations. The setting: back in the office. The key players: the engineers and, by now, the model itself. The stakes? To make the model reliable. The context: the team wanted to stop the model from making things up.
The “aha” moment: ReAct helped because the model was forced to look at the real-world result before speaking again.
Let’s say the model is asked, “What is the capital of France?” A naive model might say, “The capital of France is Berlin.” But if the model uses ReAct, the loop looks like this:
Goal: What is the capital of France?
Thought: I should verify this with a web search.
Action: Search for the capital of France.
Observation: The capital of France is Paris.
Thought: I can now answer reliably.
Response: The capital of France is Paris.If the search tool returned “Error: City not found,” the model wouldn’t be able to hallucinate an answer. It would have to react to the real-world result. The unexpected twist? ReAct transformed the model from a confident guesser into a truth-seeker. This iterative process, this constant feedback loop, was the foundation for AI’s ability to reason, solve problems, and, most importantly, learn.
Part 7: Phase 5 — The Agentic Workflow (The “Interns”)
The year is 2024. The setting: a nondescript office building in a quiet corner of Palo Alto. The key players: a team of AI researchers, led by Dr. Anya Sharma. The stakes? To build AI that could not just understand the world, but work in it. The context: the team had spent years wrestling with the limitations of LLMs. They had “brains” but lacked the ability to execute. Their breakthrough? Agentic AI — the birth of the AI “interns.”
What is an “Agent”?
The “aha” moment: an agent wasn’t just an LLM; it was a team. Imagine the office: Dr. Sharma stood before a whiteboard, a diagram scrawled across its surface.
The diagram showed the anatomy of an agent: a “Brain” (the LLM), “Memory” (a knowledge store), “Eyes” (access to information, like web search or databases), “Hands” (tools), and a “Heart” (a persona and loop). “Think of it like this,” Dr. Sharma explained. “The LLM is the senior partner - it makes the decisions. But the other components are the interns who do the actual work.”
The “Heart,” the persona, was the key. It wasn’t just about giving the AI access to tools; it was about defining its role.
The Birth of Specialized Agents
The team then began to create a series of specialized interns. The setting: the same office, now bustling with activity. The key players: the AI models, each with a specific job. The stakes? To see if these “interns” could handle real-world tasks. The context: they were training these agents on various tasks, from coding to research.
The first intern? The Planner Agent. Its job: to break down complex prompts into manageable tasks. Dr. Sharma showed an example.
For the Planner Agent, the prompt might be: “You are a project manager. Your job is to break down complex tasks into a series of actionable steps. You do not execute the steps; you only create a checklist.”
Next came the Coding Agent. Its specialty: the “Code-Execute-Debug” loop.
“You are a software engineer. Your job is to write code to fulfill user requests, run the code, and debug any errors. You have access to a sandbox environment.”
The team then introduced the Research/Instruction Agent.
“You are a research assistant. Your job is to find the most relevant information from online sources or documents to answer user questions.”
The “aha” moment: seeing the agents work together. The team set up a complex task, a request to “build a website that displays the current weather in Paris.”
- The Planner Agent broke the task into subtasks: “Research weather APIs,” “Write HTML/CSS,” “Write JavaScript to fetch and display the data,” “Test the website.”
- The Coding Agent wrote the code, ran it, and debugged the errors.
- The Research Agent found the necessary weather API.
The most surprising part? It worked. The website appeared. The team then realized they could scale this.
The Thinking/Reasoning Agent: a slower, high-logic model (like o1), used for math, logic, or architecture where speed matters less than correctness.
The Critic/Reviewer Agent: its only job is to find flaws in the other agents’ work. It’s the “quality control” at the end of the factory belt.
The unexpected connection? They had created a digital factory, a team of specialized “interns” working together to accomplish complex tasks, each playing a specific role, each contributing to the final product.
“Agentic AI systems are being used in a variety of industries, from software development to healthcare, to automate complex workflows and improve efficiency.”
The setting: back in the office. The key players: Dr. Sharma and her team. The stakes? To see the future of work. The context: the team was now focused on scaling their intern model. Dr. Sharma smiled. The future of AI wasn’t just about understanding; it was about doing.
Part 8: The Economics & Final Reflection
The Cost of Intelligence: Balancing the “Senior Brain” (expensive reasoning) with “Junior Hands” (cheap executors).
The scene: a bustling futures trading floor in 2027. The setting: a massive screen displaying real-time market data. The key players: a team of human traders, augmented by AI agents. The stakes? Millions of dollars, riding on split-second decisions. The context: the firm had invested heavily in agentic AI. Their breakthrough? Realizing that not all AI tasks were created equal.
The “aha” moment: it wasn’t about replacing human traders; it was about re-architecting the team.
The firm’s AI strategy, spearheaded by a data scientist named Anya (yes, another Anya), revolved around a cost-benefit analysis.
Some tasks demanded deep reasoning, long context windows, and careful planning. Those were routed to an expensive “senior brain” model. Other tasks were repetitive: pulling data, formatting outputs, checking templates, and running predefined tool calls. Those went to faster, cheaper executor models.
The result was a practical stack rather than a single all-purpose model. A planner reasoned, a set of tool-using workers executed, and a reviewer checked quality before delivery. This architecture reduced cost, improved consistency, and made failures easier to debug.
That is the core lesson of the intern metaphor: intelligence is no longer one giant monolith. It is organized work. When we split thinking, retrieval, action, and review into explicit roles, AI systems become more useful and more accountable.
From prompts to interns is not just a model story; it is an operating model story. The future belongs to teams that can design these workflows deliberately, measure them honestly, and keep humans responsible for the final judgment.